
Review of ALOHA and related works
Introduction
在人工智能和机器人领域,模仿学习(Imitation Learning)作为一种从专家演示中学习策略的强大方法,已经被广泛应用于复杂任务的解决。然而,模仿学习的核心挑战之一在于如何高效地表示和学习复杂的行为模式。为此,自编码器(Autoencoder)成为了模仿学习的重要起点。
自编码器通过将高维数据压缩为低维潜在表示,能够捕捉数据的关键特征,同时保留行为的核心结构。这种能力为后续更复杂的建模任务奠定了基础,使我们能够在潜在空间中更高效地建模、优化和生成行为。例如,变分自编码器(VAE)进一步引入概率分布,增强了对多样性行为的建模能力,而条件变分自编码器(CVAE)更进一步,通过加入条件信息实现了目标导向的行为学习。
从自编码器开始,不仅帮助我们理解数据的内在结构,还为更复杂的模仿学习算法(如基于生成模型的方法)提供了重要的理论和实践基础。正是从这一基础出发,模仿学习才能逐步扩展到更复杂、更多样化的应用场景。
自动编码器(Autoencoder)
自动编码器(Autoencoder) 是一种无监督学习模型,广泛应用于数据降维、特征提取和生成式建模。它的核心思想是通过一个瓶颈结构(bottleneck)对输入数据进行压缩和重建,从而学习数据的潜在表示(latent representation)。
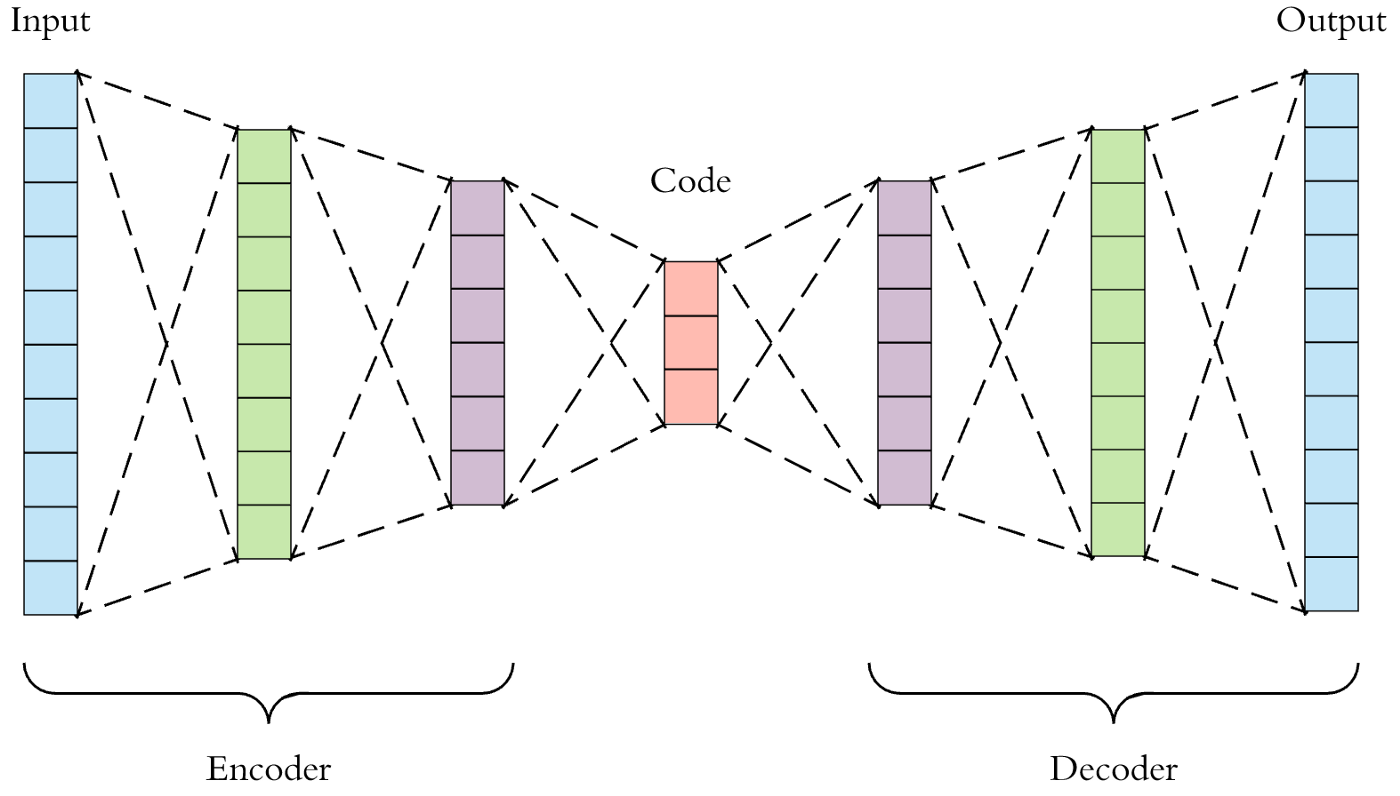
1.1. 自动编码器的结构
自动编码器通常由两部分组成:
编码器(Encoder):
将输入数据
转化为一个低维的潜在表示 : 编码器的目标是学习数据的特征并提取关键信息。
解码器(Decoder):
将潜在表示
转化回原始数据的近似值 : 解码器的目标是基于潜在表示重建原始输入。
整个过程可以表示为:
1.2. 损失函数
自动编码器的训练目标是最小化输入数据
常用的损失包括:
- 均方误差(MSE):
用于测量原始数据和重建数据之间的差异。 - 交叉熵(Cross-Entropy Loss):
适用于离散数据。
1.3. 特点与用途
(1) 特点
- 自动编码器的核心是学习数据的低维潜在表示,这种表示能够捕捉数据的主要特征。
- 模型结构灵活,可以扩展为多层深度网络(深度自动编码器)。
(2) 用途
数据降维:
- 自动编码器将高维数据压缩到低维潜在空间(如图像、文本等),可作为替代主成分分析(PCA)的方法。
特征提取:
- 潜在表示
可用作下游任务(如分类、聚类)的输入。
- 潜在表示
异常检测:
- 在输入数据偏离训练分布时,重建误差会显著增大,可用于检测异常样本。
生成模型:
- 通过解码器生成新的数据样本,例如图像生成。
1.4. 扩展类型
(1) 去噪自动编码器(Denoising Autoencoder, DAE)
将被噪声污染的数据还原为原始数据。
- 编码器学习去噪特性,增强模型鲁棒性。
(2) 稀疏自动编码器(Sparse Autoencoder)
在潜在表示
- 常用于特征提取和信息压缩。
(3) 变分自动编码器(Variational Autoencoder, VAE)
学习数据的概率分布,并从潜在空间生成新的样本。
- 在潜在空间上引入高斯分布约束,使其适用于生成式建模任务。
(4) 残差自动编码器(Residual Autoencoder, RAE)
引入残差连接,缓解深层网络中梯度消失的问题,提高重建质量。
变分自编码器 (Variational Autoencoder, VAE)
变分自编码器(Variational Autoencoder, VAE) 是一种生成式模型,是传统自动编码器(Autoencoder)的扩展版本。VAE 的目标是学习数据的潜在概率分布,并能够基于这个分布生成新样本。与普通自动编码器不同,VAE 在潜在空间上引入了概率分布的概念,从而具备生成式建模能力。
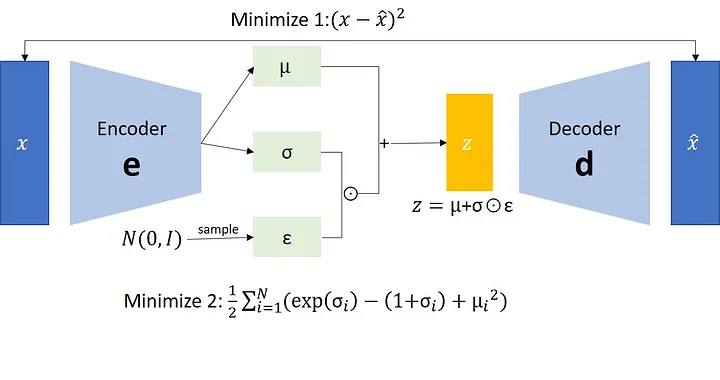
2.1. VAE 的工作原理
(1) 编码器
映射到概率分布
在普通自动编码器中,编码器将输入数据
映射为一个固定的潜在表示 。 而在 VAE 中,编码器将输入数据映射为一个高斯分布参数
,即每个输入对应一个潜在分布:
其中::
潜在分布的均值。
:
潜在分布的方差。从这个分布中随机采样一个潜在表示
,而不是固定一个值。
(2) 解码器
生成数据
解码器将从潜在空间采样得到的
映射回数据空间,生成一个近似的重建数据 :
2.2. VAE 的损失函数
VAE 的损失函数由两部分组成
(1) 重建损失(Reconstruction Loss)
衡量解码器生成的数据
与原始数据 的差异: $$
\mathcal{L}{\text{recon}} = -\mathbb{E}{q_\phi(z|x)}[\log p_\theta(x|z)]
$$目标是让解码器尽可能还原输入数据。
(2) KL 散度损失(KL Divergence Loss)
将潜在分布
与标准正态分布 对齐: $$
\mathcal{L}{\text{KL}} = \text{KL}(q\phi(z|x) || p(z))
$$目标是让
更接近标准正态分布,保证潜在空间的结构化。
总损失函数
VAE 的总损失函数可以表示为:
$$
\mathcal{L}{\text{VAE}} = \mathcal{L}{\text{recon}} + \mathcal{L}_{\text{KL}}
$$
通过最小化这两个损失,VAE 同时优化重建能力和潜在空间的分布结构。
2.3. 关键技术:
重参数化技巧(Reparameterization Trick)
在训练过程中,直接从
这意味着
每次采样时,即使输入
所以VAE 使用 重参数化技巧 将采样过程重新表述为:
其中:
是从标准正态分布中采样的噪声。 和 是由编码器学习得到的参数。
条件变分自编码器 (Conditional Variational Autoencoder, CVAE)
条件变分自编码器(Conditional Variational Autoencoder, CVAE) 是变分自编码器(VAE)的扩展版本,通过引入条件信息(condition)来控制生成样本的特性。CVAE 在生成数据时,除了依赖潜在变量

3.1. CVAE 的基本思想
- CVAE 在 VAE 的基础上,通过引入条件变量
,使编码器和解码器的映射受条件信息的影响。 - 这使得模型可以根据特定条件生成具有特定属性的数据样本。
3.2. CVAE 的结构
CVAE 的整体架构包括:
编码器(Encoder):
输入为原始数据
和条件变量 。 将它们共同映射到潜在空间,输出高斯分布的均值
和标准差 :
解码器(Decoder):
输入为潜在变量
和条件变量 。 将它们映射到数据空间,输出重建数据
:
整个生成过程可以表示为:
3.3. CVAE 的训练目标
(1) 重建损失(Reconstruction Loss)
和 VAE 类似,CVAE 的解码器需要根据
$$
\mathcal{L}{\text{recon}} = -\mathbb{E}{q_\phi(z|x, c)}[\log p_\theta(x|z, c)]
$$
(2) KL 散度损失(KL Divergence Loss)
为了使潜在分布
$$
\mathcal{L}{\text{KL}} = \text{KL}(q\phi(z|x, c) || p(z))
$$
KL 散度的定义为:
该公式描述了两个分布
- 当
时,KL 散度为 0,表示两个分布完全相同。 - 当
偏离 时,KL 散度越大,表示分布之间的差异越显著。
在 CVAE 中,我们希望通过最小化 KL 散度,让编码器生成的潜在分布
(3) 总损失函数
CVAE 的总损失函数结合了重建损失和 KL 散度损失:
$$
\mathcal{L}{\text{CVAE}} = \mathcal{L}{\text{recon}} + \mathcal{L}_{\text{KL}}
$$
3.4. CVAE 的工作流程
编码阶段:
输入数据
和条件变量 被送入编码器,生成潜在空间的参数 。 使用重参数化技巧对潜在分布进行采样,得到潜在变量
:
解码阶段:
- 将采样得到的
和条件 输入解码器,生成重建样本 。
- 将采样得到的
优化阶段:
- 最小化
,同时优化编码器和解码器的参数。
- 最小化
ALOHA系列
我们接下来看一下ALOHA系列,以及ACT算法的相关工作。
主要包括以下几篇论文:
- Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
- Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
- ALOHA Unleashed: A Simple Recipe for Robot Dexterity
这里还是以ALOHA系列的第一篇论文《Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware》为主,来介绍一下ALOHA的工作原理。
ALOHA 数据收集系统:
- 使用低成本机器人(例如 Dynamixel 电机),结合多视角摄像头,记录人类操作者的演示数据。
- 数据包括:
- 动作:记录领导者(leader robot)的关节位置,而不是跟随者(follower robot),以间接反映施加的力。
- 观察:来自 4 台摄像头的视频数据和跟随者的关节位置。
ACT(Action Chunking with Transformers)算法:
- 提出了基于条件变分自编码器(CVAE)的动作分块方法,通过 Transformer 编码器和解码器处理多模态数据。
- 编码器将动作序列和观测信息压缩为潜在变量
(style variable),捕捉动作风格和动态特性。 - 解码器结合潜在变量
、视觉特征和关节位置预测未来动作序列,并通过低级 PID 控制器实现高频控制。
解决模仿学习的局限性:
- 针对现有模仿学习方法在细粒度任务中无法适应高频控制和闭环反馈的问题,ACT 提供了一种能够精准模仿人类操作者的解决方案。
- 通过动作分块和多模态信息融合,ACT 提升了在低成本硬件上执行复杂任务的能力。
为了更好地理解 ACT 的实现,我们接下来通过下面的图详细说明 ACT 的架构及其核心组件。
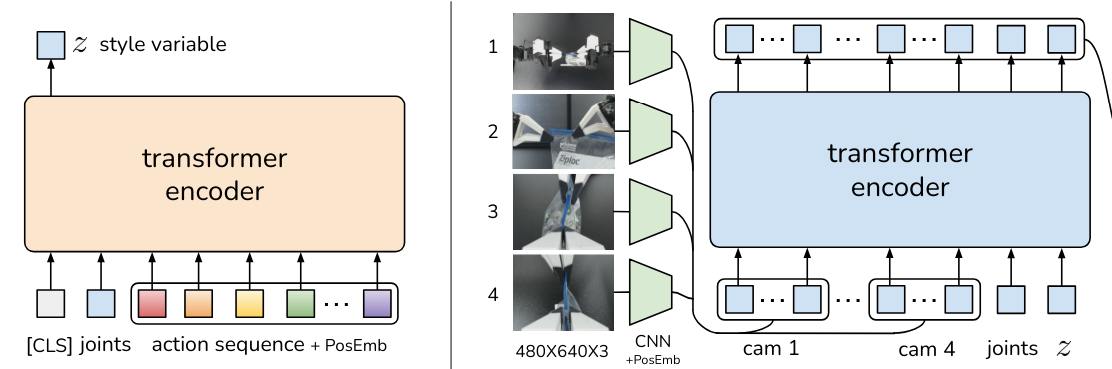
上图描述了 ACT 的关键工作流程,其核心是基于条件变分自编码器(CVAE)的设计,包括一个编码器和一个解码器:
- 左侧部分 展示了编码器如何将动作序列和关节观测压缩为潜在变量
,以捕捉动作风格。 - 右侧部分 展示了解码器如何结合视觉信息、关节位置和潜在变量
生成未来的动作序列。
接下来我们具体解析图中的每个部分,并详细说明其功能和实现方式。
4.1. 整体概述
- ACT 被训练为一个 条件变分自编码器(CVAE),包括一个编码器和一个解码器。
- 左侧(Encoder):
- 编码器的作用是压缩动作序列和关节观测数据,将它们编码为潜在变量
(即 style variable,用于表示动作风格)。 - 编码器仅在训练阶段使用,在测试时会被丢弃。
- 编码器的作用是压缩动作序列和关节观测数据,将它们编码为潜在变量
- 右侧(Decoder):
- 解码器即为 ACT 的策略网络,基于从多视角图像、关节位置以及
提供的信息,预测未来的动作序列。 - 在测试时,
被设为先验分布的均值(如零),以生成对应的动作。
- 解码器即为 ACT 的策略网络,基于从多视角图像、关节位置以及
4.2. 左侧:CVAE 的编码器

1. 输入
CVAE 的编码器接收的输入包括:
- [CLS] Token:作为句子的整体表示,初始化为固定向量,类似于 BERT 中的分类标记。
- 关节数据(joints):表示当前时间步的机器人关节位置,形状为
。 - 动作序列(action sequence):表示多时间步的动作信息(如前
至当前 的关节动作),记为 。 - 位置编码(Position Embeddings):为每个输入标记添加位置信息,用于捕捉时间序列中的顺序特征,记为
,其中 为序列长度。
[CLS] Token 是一个特殊的标记,通常用作序列整体表示的占位符。 在 Transformer 架构中,它被放在输入序列的最前面,其嵌入会在多层 Transformer 编码器中更新,最终聚合整个序列的信息。类似于 BERT 模型中,[CLS] 标记的最终表示可以用来执行分类、回归或其他全局任务。在 ACT 的编码器中,[CLS] Token 的表示用于生成潜在变量
,以捕捉动作序列的整体风格特性。
2. 编码器处理的数学表示
编码器的作用是将输入序列压缩为潜在变量
(1) 输入嵌入
输入序列包括
其中:
- $\mathbf{W}e \in \mathbb{R}^{d\text{in} \times d_\text{model}}$:嵌入矩阵。
:输入标记(如动作、关节数据)。 :位置编码,捕捉时间步的顺序信息。 :Transformer 模型的隐藏层维度。
整个输入序列可以表示为:
$$
\mathbf{H}^{(0)} = [\mathbf{h}_0^{(0)}, \mathbf{h}_1^{(0)}, \dots, \mathbf{h}n^{(0)}]
$$
其中 $\mathbf{H}^{(0)} \in \mathbb{R}^{n \times d\text{model}}$。
(2) Transformer Encoder 的处理
Transformer Encoder 通过多层堆叠来捕捉输入序列的全局上下文关系。每一层包括:
多头自注意力(Multi-Head Self-Attention, MHSA):
自注意力机制通过计算序列中每个标记之间的相关性,为每个标记分配不同的权重。
自注意力的核心公式为:
其中::查询矩阵。 :键矩阵。 :值矩阵。 :查询和键的维度。
多头自注意力结合多个注意力头,表示为:
前向全连接网络(Feed-Forward Network, FFN):
- FFN 是独立作用于每个序列位置的两层全连接网络,公式为:
- FFN 是独立作用于每个序列位置的两层全连接网络,公式为:
层归一化与残差连接(Layer Norm + Residuals):
- 每一层的输出通过残差连接与归一化增强训练稳定性:
- 每一层的输出通过残差连接与归一化增强训练稳定性:
经过
(3) 潜在变量
编码器的最终目标是将输入压缩为潜在变量
,用于表示动作的风格。使用 [CLS] Token 的嵌入表示作为序列的全局信息:
$$
\mu = \mathbf{W}\mu \cdot \mathbf{h}\text{CLS}^{(L)}, \quad \log \sigma^2 = \mathbf{W}\sigma \cdot \mathbf{h}\text{CLS}^{(L)}
$$
其中:- $\mathbf{W}\mu
\mathbf{W}\sigma$:分别是均值和标准差的线性变换矩阵。 和 :表示潜在分布 的参数。
- $\mathbf{W}\mu
通过重参数化技巧从分布中采样:
即为编码器生成的潜在变量,捕捉了输入序列的整体风格特性。
4.3. 右侧:CVAE 的解码器

4.3.1. 输入
解码器的输入包括以下三部分:
图像特征(Images)
- 从 4 台摄像头捕获的图像,分辨率为
。 - 每张图像通过 CNN 提取特征,生成尺寸为
的特征图: - 然后,将特征图展平为序列形式,并添加位置编码:
$$
\mathbf{f}_{\text{image}i} = \text{Flatten}(\mathbf{f}{\text{image}_i}) + \mathbf{p}_i \in \mathbb{R}^{N \times d}
$$
其中:是特征图展平后的长度。 是位置编码,用于捕捉空间顺序关系。
- 从 4 台摄像头捕获的图像,分辨率为
关节位置(Joints)
- 当前时间步的机器人关节位置,记为:
- 通过线性变换扩展维度,与图像特征对齐:
$$
\mathbf{f}{\text{joints}}’ = \mathbf{W}{\text{joints}} \cdot \mathbf{f}{\text{joints}} + \mathbf{b}{\text{joints}} \in \mathbb{R}^{N \times d}
$$
- 当前时间步的机器人关节位置,记为:
潜在变量(
) - 编码器生成的潜在变量
,捕捉动作序列的风格特性。 - 对
进行广播,使其与时间序列匹配:
- 编码器生成的潜在变量
4.3.2. 输入的整合
将上述三部分输入特征整合为一个序列:
$$
\mathbf{F}{\text{input}} = [\mathbf{f}{\text{image}1}, \mathbf{f}{\text{image}2}, \mathbf{f}{\text{image}3}, \mathbf{f}{\text{image}4}, \mathbf{f}{\text{joints}}’, \mathbf{f}z]
$$
其中 $\mathbf{F}{\text{input}} \in \mathbb{R}^{M \times d}
4.3.3. 解码过程的公式表示
解码器采用 Transformer Decoder 处理输入特征序列,生成未来的动作序列。Transformer Decoder 包括以下组件:
多头注意力机制(Multi-Head Attention, MHA)
解码器的 MHA 通过注意力机制捕捉输入序列中不同模态特征之间的全局关系。
计算过程为:
其中:分别为查询、键、值矩阵。 是查询和键的维度。
多头注意力结合多个独立注意力头:
位置编码与残差连接
- 为了捕捉时间步的顺序关系,输入序列添加了固定的位置编码:
$$
\mathbf{F}{\text{pos}} = \mathbf{F}{\text{input}} + \mathbf{p}
$$ - 同时,使用残差连接和归一化增强训练稳定性:
$$
\mathbf{F}{\text{output}} = \text{LayerNorm}(\mathbf{F}{\text{pos}} + \text{MHSA}(\mathbf{F}_{\text{pos}}))
$$
- 为了捕捉时间步的顺序关系,输入序列添加了固定的位置编码:
前向传播网络(Feed-Forward Network, FFN)
- FFN 是每个时间步独立应用的全连接网络,公式为:
- FFN 是每个时间步独立应用的全连接网络,公式为:
多层堆叠
- 经过多层 Transformer Decoder 堆叠后,解码器输出未来的动作序列表示。
4.3.4. 输出的公式表示
解码器的最终输出是未来的动作序列,即机器人两只手臂的目标关节位置:
$$
\mathbf{a}{t+1:t+n} = \text{Decoder}(\mathbf{F}{\text{output}})
$$
其中:
,表示未来 个时间步的目标关节位置。 - 这些目标位置将由低级 PID 控制器执行,保证高频控制的准确性。
4.4 Transformer-based CVAE
先回顾一下CVAE的结构:
- 编码器(Encoder):从输入数据
和条件变量 中学习潜在分布 ,输出潜在变量 。 - 解码器(Decoder):根据潜在变量
和条件变量 重建输入数据 。
Transformer-based Encoder 是 CVAE 的 编码器部分 的具体实现,二者是嵌套关系,Transformer 为 CVAE 提供了强大的序列建模能力,以下是它们的关系和具体关联:
(1) 输入到编码器的特征
CVAE 的编码器需要处理复杂的多模态数据,包括:
- 当前时间步的机器人关节位置(joints)。
- 动作序列(action sequence)。
- 位置编码(Position Embeddings)。
这些输入特征被送入 Transformer Encoder,编码为潜在变量。
(2) Transformer 提供序列建模能力
Transformer-based Encoder 利用了 自注意力机制(Self-Attention) 和 位置编码,能够捕捉时间序列数据中的全局依赖关系:
Transformer Encoder 的多头注意力机制能有效建模多模态特征(如动作序列与关节位置)的复杂关联。
(3) 潜在变量
Transformer Encoder 的最终输出(例如 [CLS] Token 的嵌入)被映射为高斯分布的参数(
$$
\mu = \mathbf{W}\mu \cdot \mathbf{h}\text{CLS}, \quad \log \sigma^2 = \mathbf{W}\sigma \cdot \mathbf{h}\text{CLS}
$$
重参数化技巧将其采样为潜在变量
3. Transformer-based Encoder 对 CVAE 的贡献
Transformer-based Encoder 是 CVAE 编码器的具体实现,与传统的全连接网络或卷积网络相比,它的引入为 CVAE 带来了以下优势:
更强的序列建模能力, Transformer 的自注意力机制 能捕捉时间序列中长距离的依赖关系,非常适合处理动作序列和多模态数据(如视觉特征与关节位置)的复杂交互。
多模态特征的融合, Transformer 能同时处理不同模态的特征(如图像、关节位置和动作序列),并将它们的关系建模为全局上下文信息,这对 CVAE 编码器处理多模态数据至关重要。
高效的潜在变量表示, Transformer Encoder 能生成更加高效、结构化的潜在变量
,提升了解码器的生成质量,使 CVAE 更加适合高频控制和精细任务。
4.5 在测试阶段为什么丢弃编码器?
4.5.1. 潜在变量
潜在变量
的意义: - 在 CVAE 框架中,潜在变量
是对输入数据(如动作序列、观察等)进行压缩的结果,它捕捉了输入数据的全局特性或风格(如动作风格)。 - 在训练阶段,编码器会从输入数据中生成
,确保其包含有效的特征信息,从而能够指导解码器生成高质量的输出。
- 在 CVAE 框架中,潜在变量
测试阶段的假设:
- 在测试阶段,模型不再能访问训练数据(即未见的观察数据),此时编码器无法继续从输入数据中生成
。 - 因此,使用
作为一种固定的、先验的假设,用以生成动作序列。
- 在测试阶段,模型不再能访问训练数据(即未见的观察数据),此时编码器无法继续从输入数据中生成
4.5.2. 为什么测试阶段可以直接将
训练目标确保
的分布接近先验分布: - 在训练阶段,KL 散度损失会强制编码器生成的潜在分布
接近标准正态分布(先验分布 )。 - 由于 KL 散度的约束,模型已经学习到如何在
的假设下重建输入数据。 - 在测试阶段,直接将
设为先验分布的均值(即 )是合理的近似,因为训练中模型已经适应了这种分布。
- 在训练阶段,KL 散度损失会强制编码器生成的潜在分布
避免对
的依赖: - 测试阶段的主要目标是验证解码器的生成能力,而不依赖编码器。
- 在很多生成任务中,
的风格化特性并不是必须的,尤其是当解码器已经学习到如何根据其他条件(如观察数据或任务需求)生成合理的动作时。
减少计算复杂度:
- 编码器的计算可能很复杂(特别是在 Transformer 架构下),在测试阶段丢弃编码器可以简化推理过程,提高实时性。
实际任务的独立性:
- 在许多实际任务中,测试环境中的输入数据可能与训练环境的分布有差异,直接依赖编码器生成
可能导致分布偏移(out-of-distribution)。 - 固定
可以规避这一问题,确保生成过程稳定。
- 在许多实际任务中,测试环境中的输入数据可能与训练环境的分布有差异,直接依赖编码器生成
4.5.3. 如果
训练阶段的学习过程依赖编码器:
- 编码器是训练过程中不可或缺的部分,用于将输入数据映射到潜在空间,并学习数据的全局特性。
- 编码器通过生成
,为解码器提供了更丰富的条件信息,从而帮助解码器更好地学习如何生成输出。
潜在空间的学习约束:
- 编码器通过 KL 散度约束,将潜在分布
对齐到先验分布 ,确保潜在空间结构化。 - 这一过程使得解码器能够在训练阶段学会如何处理
的假设。
- 编码器通过 KL 散度约束,将潜在分布
提升模型的生成能力:
- 训练阶段的编码器生成的
可以捕捉训练数据的风格特性(如动作的动态特性),帮助解码器更有效地拟合训练数据。 - 即使在测试阶段使用
,这种风格信息在训练过程中对解码器的影响依然存在,提升了解码器的生成能力。
- 训练阶段的编码器生成的
未来扩展的潜力:
- 如果需要更复杂的生成(如不同风格的动作序列),仍可以在测试阶段通过采样非零的
来引入更多样性。因此,编码器在训练阶段的重要性依然不可忽视。
- 如果需要更复杂的生成(如不同风格的动作序列),仍可以在测试阶段通过采样非零的
代码
[Future Work]
- Title: Review of ALOHA and related works
- Author: xiangyu fu
- Created at : 2024-11-26 18:36:47
- Updated at : 2025-12-10 16:10:05
- Link: https://redefine.ohevan.com/2024/11/26/Reviews/aloha/
- License: This work is licensed under CC BY-NC-SA 4.0.