
-
Review of FOWM (Finetuning Offline World Models)
离线强化学习(offline RL),作为一种无需在线交互就能在预先存在的数据集上训练策略的框架。然而,将算法限制在固定数据集上会导致状态-动作分布偏移(state-action distribution shift),即训练和推理阶段的分布不一致,... -
Review of ALOHA and related works
Introduction在人工智能和机器人领域,模仿学习(Imitation Learning)作为一种从专家演示中学习策略的强大方法,已经被广泛应用于复杂任务的解决。然而,模仿学习的核心挑战之一在于如何高效地表示和学习复杂的行为模式。为此,自编码器... -
Review of VQ-BeT
引言VQ-BeT(Vector-Quantized Behavior Transformer) 是一种结合向量量化(Vector Quantization)和Transformer架构的行为建模方法,专为多模态连续动作的学习与预测而设计。它通过 残差... -
How to use UDP and mDNS on ESP32
IntroductionIn this tutorial, I will walk through using UDP and mDNS with the ESP32 platform. I’ll cover how to set up UDP co... -
How to conect an Ubuntu system to a hardware device using DHCP
Step 1: Connect the Ethernet Cable Plug one end of the Ethernet cable into your Ubuntu machine’s Ethernet port and the other ... -
Model-based vs. Learning-Based, which is better?
I had the opportunity to attend a seminar on robotics hosted by three distinguished MIT PhD students today. It is about motor... -
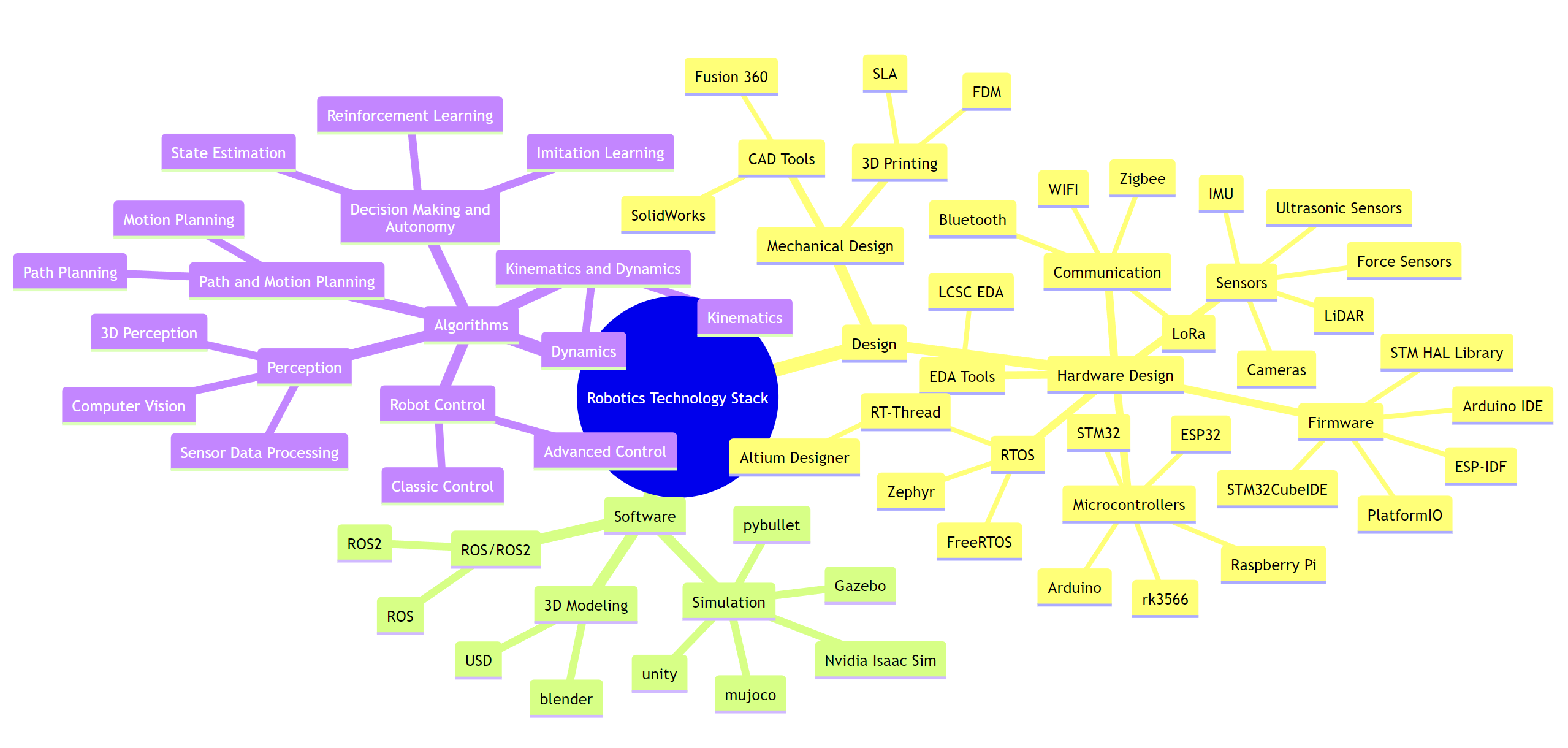
Robotics Technology Stack
Recently, I felt the need to organize robotics technology stack to identify any deficiencies. It also serves as a review and commentary on my experiences over the past few years.
-
DQN 04 - Actor-Critic Methods
4.1 简介在强化学习中,Actor-Critic方法是一种结合策略优化(policy optimization)和价值评估(value estimation)的方法。它通过将策略网络(Actor)和价值网络(Critic)结合在一起,提高了智能体的... -
DQN 03 - Proximal Policy Optimization
在强化学习(2)中介绍了REINFORCE算法。但REINFORCE算法还是存在三个问题: 更新过程效率很低,我们运行一次策略,更新一次,然后丢弃该轨迹。 梯度估计是嘈杂的。随机收集的轨迹可能无法代表该策略。 没有明确的可信度赋值。一个轨迹可能包含... -
DQN 02 - Policy Gradient Method
引言在之前介绍的方法中,几乎所有方法都是动作价值方法(action-value Method),通过学习动作价值并基于动作价值来学做动作。如果没有动作价值评估,他们的策略甚至不会存在。但在这个部分我们将考虑学习参数化策略的方法,这些方法可以在不考虑价...
